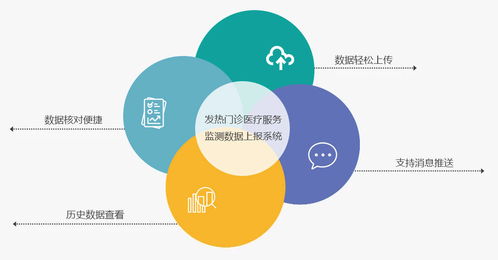
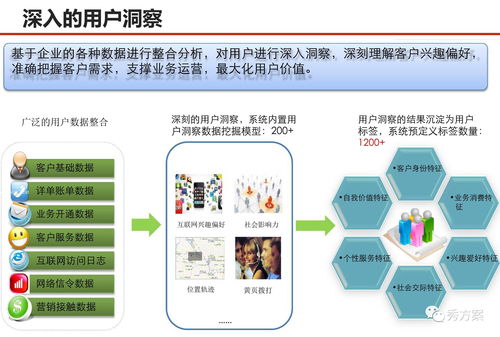
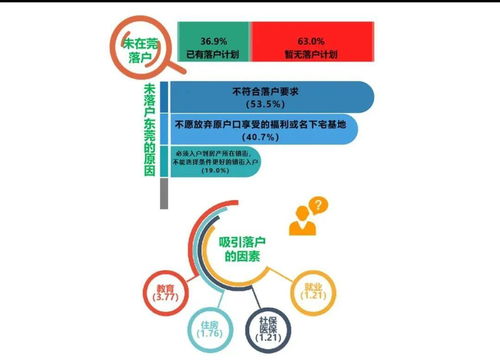
数据与数据处理服务 微服务架构中的角色辨析
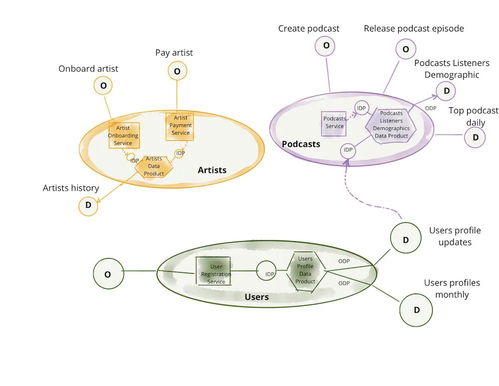
在当今的软件架构领域,特别是微服务架构日益普及的背景下,一个常见的概念混淆在于“数据”与“数据处理服务”之间的关系。许多人会下意识地将“数据”本身视为一个“微服务”,这是一个需要澄清的关键点。本文将探讨为什么数据本身并非微服务,而围绕数据构建的“数据处理服务”才是微服务架构中的核心组件,并分析两者在微服务生态系统中的不同角色与最佳实践。
核心辨析:数据是资产,服务是能力
必须明确一个基本前提:数据(Data)本身是一种静态的、被管理的资产或资源。它可以是结构化的数据库记录、非结构化的文档、流式的事件日志,或是任何形式的信息载体。数据本身不具备主动性、逻辑性或网络端点;它不“运行”,也不直接“响应”请求。它存储在数据库、数据湖、消息队列或文件系统中,等待被访问、操作或分析。
相反,数据处理服务(Data Processing Service)是一个动态的、可独立部署和扩展的软件组件,它是微服务架构中的一个具体服务。这个服务封装了特定的业务能力——即对数据进行操作、转换、验证、聚合、分析或提供访问的逻辑。它通过定义良好的API(如RESTful接口、gRPC或消息订阅)与其他服务通信,管理自身的数据存储(遵循微服务中的数据库私有模式),并作为一个独立的进程运行。例如,一个“用户信息服务”负责管理用户个人数据的增删改查;一个“订单分析服务”负责处理订单数据并生成业务报告。
为什么数据本身不是微服务?
- 缺乏封装性:微服务的核心原则之一是“围绕业务能力组织服务”和“高内聚、低耦合”。一个纯粹的“数据”实体(如“用户表”或“产品目录”)并不封装业务逻辑。它只是信息的集合。真正的微服务会封装与这些数据相关的完整操作流程与规则。
- 不可独立部署与扩展:微服务应能独立于其他服务进行部署、升级和水平扩展。数据存储(如一个MySQL实例)虽然可以独立扩展,但“数据”这个概念本身并不等同于一个可执行、可部署的应用单元。扩展的是存储容量或性能,而非业务功能。
- 没有明确的API边界:微服务通过API暴露其功能。原始数据本身没有API;它需要通过一个服务层来提供受控的、安全的访问。直接暴露数据库给其他服务会破坏服务边界,导致紧密耦合和数据模型泄露,这正是微服务架构试图避免的。
- 不处理通信与弹性:微服务需要处理服务发现、负载均衡、容错、网络通信等。数据作为静态资产,不参与这些活动。
数据处理服务作为微服务的典型特征
一个设计良好的数据处理微服务通常具备以下特征:
- 专属数据所有权:服务拥有其领域内数据的绝对控制权,外部只能通过其API访问数据。这避免了服务间直接共享数据库,确保了边界清晰。
- 封装业务逻辑:服务内部包含了所有与数据相关的业务规则、验证、计算和流程。例如,在创建订单时计算折扣,而不仅仅是插入一条记录。
- 提供精确定义的API:对外提供一套契约化的接口,其他服务通过调用这些接口来请求数据或触发数据处理操作。
- 可独立运维:可以单独进行技术栈选型、部署、监控和扩展,而不影响系统中其他服务。
实践意义与架构启示
理解“数据不是微服务,数据处理服务才是”具有重要的实践意义:
- 避免分布式单体:如果只是简单地将数据库表“拆分”并给每个表配一个简单的CRUD代理,而不封装业务逻辑,本质上创建了一个“分布式单体”,失去了微服务的优势。真正的服务应围绕业务领域(如“客户管理”、“库存管理”)而非数据实体来构建。
- 明确服务边界:这有助于设计清晰的领域驱动设计(DDD)中的限界上下文。每个上下文内的领域模型和数据由对应的服务管理。
- 数据一致性与集成:由于数据被各个服务私有化,服务间数据一致性需要通过Saga、事件驱动架构(发布领域事件)等模式来保证,而不是依赖数据库事务。这促进了松耦合和系统弹性。
- 技术多样性:不同的数据处理服务可以根据其需求选择最适合的数据存储技术(SQL、NoSQL、缓存等),实现“多语言持久化”。
结论
在微服务架构的蓝图中,数据是皇冠上的宝石,而数据处理服务则是守护并雕琢这颗宝石的工匠。将关注点从“拥有数据”转移到“提供数据能力”是成功实施微服务的关键。架构师和开发者应该致力于构建一个个内聚的、自治的数据处理服务,这些服务通过协作来管理整个系统的数据生命周期,从而支撑起灵活、可扩展且富有弹性的现代应用系统。记住,我们构建的是服务网格,而不是一个被简单分割的分布式数据库。
如若转载,请注明出处:http://www.xinsiby.com/product/6.html
更新时间:2026-06-19 17:56:37