Flink数据集成服务在小红书的降本增效实践
在当今大数据驱动的互联网时代,高效、稳定、低成本的数据处理能力已成为企业核心竞争力的关键组成部分。小红书作为国内领先的生活方式平台和消费决策入口,每天面临着海量用户行为日志、内容数据、交易信息等多源异构数据的实时集成与处理挑战。为应对这一挑战,小红书技术团队深度应用Apache Flink构建了新一代数据集成服务,在保障数据时效性与一致性的显著实现了降本增效的目标。
一、 背景与挑战:传统数据处理架构的瓶颈
小红书早期的数据处理架构依赖于多套批处理系统与流处理系统的组合。这种架构存在几个显著痛点:数据链路冗长,从数据产生到可供分析或服务调用,延迟较高,难以满足实时推荐、风控等业务场景的毫秒级需求;维护成本高昂,需要多套技术栈的运维团队,且系统间数据同步复杂,容易出错;资源利用率不均衡,批处理任务通常在闲时资源闲置,流处理任务在高峰时段资源紧张,无法实现弹性伸缩。这些瓶颈制约了业务创新速度,也带来了巨大的计算与存储成本压力。
二、 核心方案:基于Flink的统一数据集成服务
为了突破瓶颈,小红书选择了Apache Flink作为统一数据集成与处理的引擎,构建了流批一体、存算分离的新架构。
- 流批一体,简化架构:利用Flink同时支持流处理和批处理的能力,将原本分离的实时ETL(抽取、转换、加载)和离线T+1数据同步任务统一到同一套框架中。这不仅大幅减少了系统复杂性和运维成本,更通过统一的SQL或DataStream API降低了开发门槛,提升了开发效率。
- 统一数据源与目标连接:服务内置了丰富的Connector,能够高效对接小红书内部各种数据源(如Kafka、MySQL、HDFS、ClickHouse等)和数据目的地。通过配置化方式,业务方可快速创建从源到目的地的数据同步任务,无需关注底层传输细节。
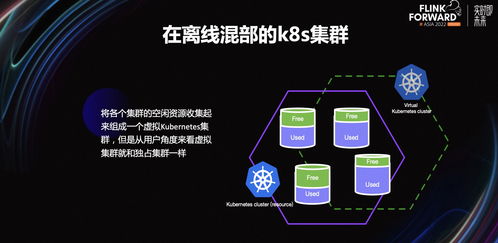
- 精准的弹性扩缩容与资源调度:与公司内部的容器化平台深度集成,该服务能够根据数据流量和任务负载,动态调整Flink作业的并发度和资源分配。在业务低峰期自动缩减资源以节省成本,在高峰时段快速扩容保障时效性,实现了计算资源的精细化管理和成本优化。
三、 降本增效的具体实践与成效
通过上述架构革新与精细运营,小红书的数据集成服务取得了显著的经济效益与效率提升。
- 成本显著降低:
- 计算成本:通过流批一体消除了冗余的批处理集群,并结合弹性伸缩,使整体计算资源消耗下降了约30%。
- 存储成本:引入高效的列式存储格式和智能分层存储策略,对历史数据实现冷热分离,降低了长期存储开销。
- 运维成本:统一的平台减少了约50%的日常运维人力投入,团队能更专注于服务优化与业务支持。
- 效率大幅提升:
- 开发效率:配置化、SQL化的开发模式使新数据链路的搭建时间从“天级”缩短到“小时级”,甚至“分钟级”。
- 数据时效:端到端的数据延迟从原来的分钟级优化至秒级甚至亚秒级,有力支撑了实时搜索排序、内容安全审核、实时数仓等关键业务。
- 数据质量:服务内置了完善的数据质量监控和告警机制,能够及时发现并处理数据丢失、延迟、格式错误等问题,保障了下游数据消费的准确性和可靠性。
四、 未来展望
Flink数据集成服务已成为小红书数据处理体系的中枢神经。团队将继续在以下几个方向深化探索:
- 智能化运维:引入机器学习算法,实现更精准的故障预测、根因分析与自动调优。
- 全链路数据治理:将数据集成服务与元数据管理、数据血缘、数据安全模块更紧密地结合,提供一站式的数据治理能力。
- 云原生深度融合:进一步拥抱云原生技术栈,探索Serverless模式,追求极致的弹性与成本效益。
小红书基于Flink的数据集成服务实践,是一次成功的以先进技术驱动基础设施升级的典范。它不仅有效解决了大规模数据处理中的成本与效率矛盾,更通过提供稳定、高效、易用的数据流水线,为小红书各项业务的快速增长与创新奠定了坚实的数据基石。
如若转载,请注明出处:http://www.xinsiby.com/product/7.html
更新时间:2026-06-19 15:55:52